
随着在线视频内容的指数级增长,从海量未经剪辑的视频中准确检索和定位特定时刻成为了多媒体理解领域亟待解决的问题。视频时序定位(TSGV)和视频语料库时刻检索(VCMR)技术旨在找到与自然语言查询语义相一致的具体视频片段。然而,现有的模型在处理包含关键语义的极短“微时刻(Micro-moments)”时,面临着语义特征高度压缩以及上下文依赖复杂的挑战,导致模型极易出现预测偏差。同时,在面对大规模视频语料库的检索时,传统的判别式方法往往依赖浅层的视觉-文本特征匹配,容易陷入表面特征匹配的陷阱,难以捕捉细粒度的语义差异并实现精确的时间边界对齐。
为此,我院吉炜副教授团队针对上述在微时刻时序定位与大规模视频检索中面临的多重挑战展开了深入研究,提出了创新的深度学习框架与特征对齐策略。本系列工作与腾讯元宝、新加坡国立大学、南洋理工大学、新加坡管理大学、浙江大学等团队紧密合作完成,相关技术成果在智能视频搜索引擎、多模态AI交互助手、海量视频内容自动化审查以及个性化视频推荐系统等应用方向具有广阔的落地前景,能够显著提升视频的细粒度理解与跨模态交互能力。相关工作分别被多媒体领域国际顶级期刊(IEEE TMM)以及信息检索领域顶级会议(ACM SIGIR 2026)接收发表。
工作一:面向微时刻视频时序定位的动态图增强事件细化方法
现有的视频时序定位(TSGV)方法在定位极短的微时刻信号时,往往难以提取有效的鉴别性特征,受制于视频极低的信噪比问题。为了解决这一核心挑战,研究团队提出了一种专门针对微时刻时序句子定位(Micro-TSG)任务的动态图增强事件细化框架。该框架首先构建特定于查询的事件感知模块,利用注意力机制从繁杂的视频特征中过滤掉与查询无关的事件信息,从而提取出与文本查询高度相关的密集事件特征。为了有效应对微时刻中强噪声和弱信号提取难的问题,团队创新性地引入了图信息瓶颈原则,设计了动态信息传播模块。该模块通过最大化压缩原始噪声图中的冗余上下文,同时严格保留时序定位所需的最关键、最具辨别性的信息,从而自动且动态地优化了跨模态注意力区域的图结构。大量实验证明,该方法在Charades-STA和TACOS等主流基准数据集上显著超越了现有的技术,实现了极高精度的微时刻边界定位效果。该工作已被多媒体领域顶级期刊IEEE TMM("Dynamic Graph-enhanced Event Refinement for Temporal Sentence Grounding of Micro-moments")接收发表。
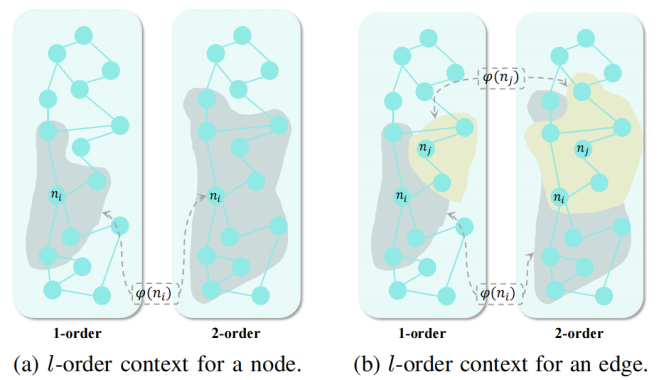
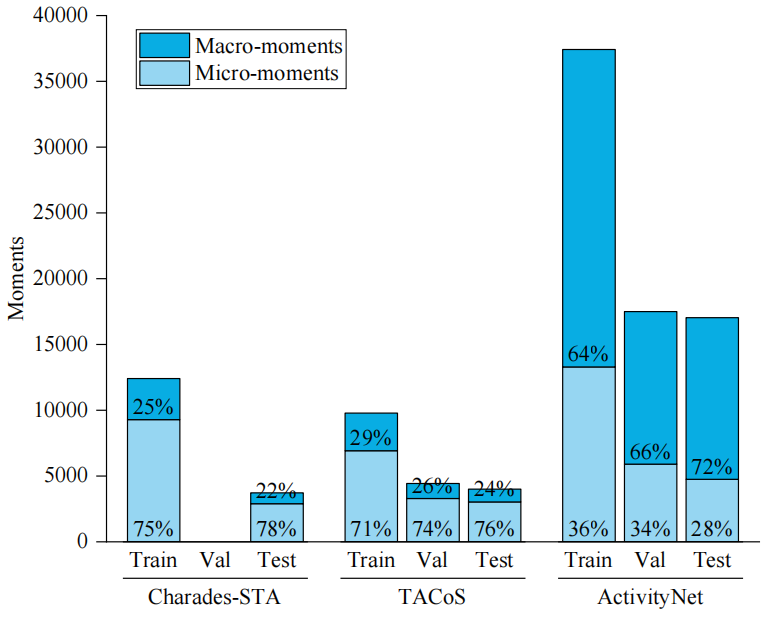
图1:动态信息传播中节点和边的阶上下文 图2:视频时序定位数据集中微时刻和长时刻的分布
工作二:生成式增强的视频语料库时刻检索
在视频语料库时刻检索(VCMR)任务中,现有的判别式模型缺乏验证密集对应关系的内在机制,通常优先考虑特征的可分离性而非深度理解,这导致注意力分布发散,难以划定精确的动作时间边界。为此,研究团队提出了一种名为Video-GAR的新型检索框架,将传统任务从表面的判别式匹配重构为深度的生成式理解。该框架首先构建了Bi-Mamba主干网络,利用状态空间模型的线性计算复杂度优势,高效捕捉海量视频中的长距离时间依赖关系,打破了传统Transformer自注意力机制带来的二次计算复杂度瓶颈。随后,团队创新性地引入了生成式增强融合模块,将文本查询重建作为辅助的生成目标,利用语言模型提供的自监督信号隐式地校准跨模态的注意力分布。该生成式解码器仅在训练阶段作为语义正则化器使用,这使得模型在不增加任何额外推理开销的情况下,显著提升了语义对齐与检索的精度。Video-GAR在实现大规模高效检索的同时,确保了帧级别的定位精度,在复杂基准数据集上实现了检索速度和定位准确率的有效平衡。该工作已被信息检索领域顶级会议ACM SIGIR 2026("Generation-Augmented Video Corpus Moment Retrieval")接收发表。
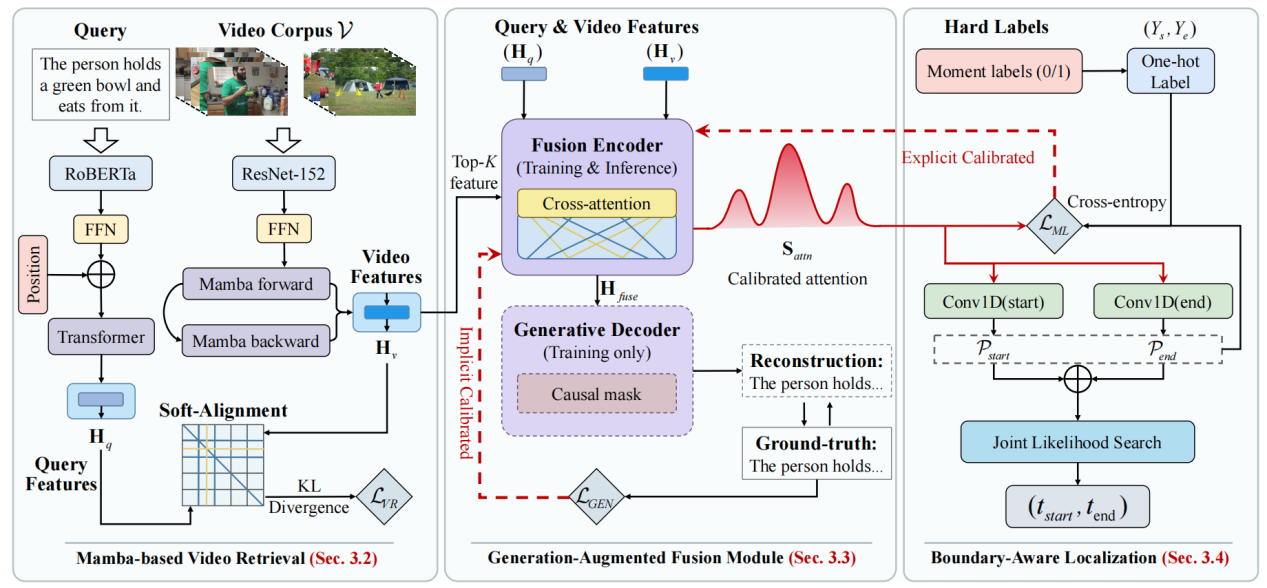
图3:Video-GAR的检索框架图