
ECCV 2024近日放榜,南京大学智能科学与技术学院七项工作被录用。ECCV (欧洲计算机视觉会议,European Conference on Computer Vision)是国际计算机视觉与模式识别领域的三大顶级会议之一,今年9月份将在意大利米兰举行。

工作一:Jiajun Hu, Jian Zhang, Lei Qi, Yinghuan Shi and Yang Gao. Learn to Preserve and Diversify: Parameter-Efficient Group with Orthogonal Regularization for Domain Generalization. In European Conference on Computer Vision (ECCV), 2024.
项目主页:https://github.com/JudgingH/PEGO
近年来,由于其海量的参数及庞大的训练数据集,基础模型已在多项任务上展现出色的泛化能力。然而,课题组注意到当直接将基础模型用于具有较大分布差异的领域泛化任务时,基础模型的泛化性能反而相比常规小模型更低。针对此问题,课题组对微调后的基础模型的泛化能力进行研究,调研了近期热门的参数高效微调技术,通过所设计的正交正则化损失对其进行分析改进,有效提升了模型的分布外泛化能力。
具体地,提出将一组参数高效的低秩适应模块注入到预训练基础模型中,并利用所提出的正交正则化损失来增强模型的泛化能力。该方法有效地保留了预训练模型的泛化能力并促使模型学习到更为多样化的知识,抑制了模型对于源域数据的过拟合。论文在五个常见领域泛化基准数据集上进行了多项对比实验和消融实验,相比于多种类型的基线方法取得了最高的平均准确率。此外,论文方法可以应用于任何含有线性层的神经网络,同时对于训练开销是友好的,且无需增加额外的测试成本。

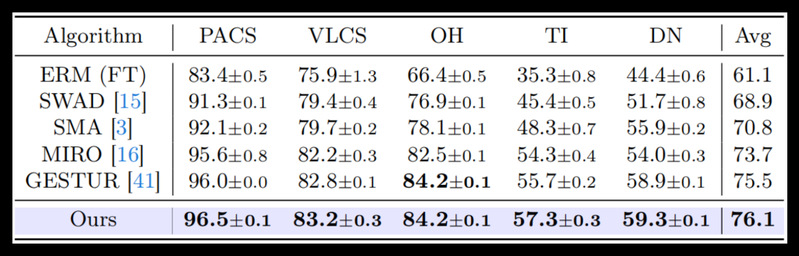

工作二:Muyang Qiu, Jian Zhang, Lei Qi, Qian Yu, Yinghuan Shi, Yang Gao. The Devil is in the Statistics: Mitigating and Exploiting Statistics Difference for Generalizable Semi-supervised Medical Image Segmentation. In European Conference on Computer Vision (ECCV), 2024.
项目主页:https://github.com/qiumuyang/SIAB
多中心可泛化的医学图像分割旨在关注如何提高分割模型在不同医疗机构、设备和患者群体上的泛化能力。然而,传统医疗图像分割领域泛化方法需要对多个领域的训练数据全部进行像素级标注,势必会引入较高的标注成本。因此,论文关注近期提出的医疗图像半监督领域泛化问题,利用采集于不同领域的少量有标注和大量无标注数据,在减少标注量的同时,提高分割模型的泛化能力。
具体地,该工作在一致性正则化的半监督训练范式下,提出了一种基于归一化层统计量独立和聚合的多分支结构,以提高领域偏移影响下的伪标签质量。此外,论文通过灰度直方图匹配和随机选择归一化分支以模拟领域分布差异,构造额外的图像和特征级别一致性正则化约束项,丰富训练阶段模型所见分布,进一步提升模型的泛化能力。所提出方法在多个多中心医疗图像分割数据集上进行验证,相比较目前该领域的最新方法,均取得较好结果。


工作三:STAG4D: 基于时空锚定的生成式4D高斯泼溅
最近,在预训练扩散模型和3D生成方面的进展激发了人们对4D内容创作的兴趣。然而,实现具有空间-时间一致性的高保真4D生成仍然是一项挑战。针对这个挑战,南京大学智能科学与技术学院三维视觉实验室(NJU-3DV)提出了STAG4D,这是一个新颖的框架,它结合了预训练的扩散模型和动态3D高斯泼溅技术,用于高保真4D生成。借鉴3D生成技术,我们使用多视图扩散模型来初始化锚定在输入视频帧上的多视图图像,其中视频输入既可以是现实世界捕获的,也可以是由视频扩散模型生成的。
具体来说,为了确保多视图序列初始化的时间一致性,我们引入了一个简单但有效的注意力融合策略,我们在自注意力计算中使用第一帧作为时间锚定。通过这种策略生成了几乎一致的多视图序列之后,我们应用得分蒸馏采样来优化4D高斯点云。与此同时,我们提出了一种自适应密集化策略,以减轻不稳定的4D高斯泼溅训练梯度,以实现稳健的优化过程。值得注意的是,所提出的流程不需要对扩散网络进行任何预训练或微调,为4D生成任务提供了一个更实用的解决方案。广泛的实验表明,我们的方法在渲染质量、空间-时间一致性和生成稳健性方面优于之前的4D生成工作,为包括文本、图像和视频在内的多样化输入设定了新的4D生成的最高水平。该工作已经被计算机视觉顶级会议ECCV 2024 接收。

图:STAG4D算法结构示意图
工作四:CHAMP:三维姿态驱动的人物动画合成
在人物舞蹈视频生成任务中,目前的主流方法通过骨架序列视频作为控制信号。然而,这类简单的二维控制信号存在闪烁,跳变等问题,在表达复杂动作时存在较大困难。针对这些问题,南京大学智能科学与技术学院三维视觉实验室(NJU-3DV)联合复旦大学生成式视觉实验室探索了将三维信息引入舞蹈视频生成任务,利用SMPL三维人体模型提供具有高度一致性的三维控制信号,并提出相应解决算法CHAMP。
具体而言,CHAMP算法根据驱动视频,预测出驱动视频中人物的SMPL参数序列,渲染成深度、法线、语义信息图等三维控制信号,结合二维骨架信息,联合输入控制信号编码器,提供了丰富且具有高度一致性的控制信息。结合参考网络和运动信息模块,实现了可控且一致的人物舞蹈视频生成。实验结果表明,CHAMP算法在多个公开数据集上的效果明显优于对比算法,验证了其有效性。该工作已被计算机视觉顶级会议ECCV 2024接收。

图:CHAMP算法示意图
工作五:Head360:高保真全角度三维头部生成与驱动
创建一个360度可渲染的三维数字人头部模型是一项非常具有挑战性的任务。尽管此前的研究工作已经展示了利用虚拟合成数据构建这种参数化人头模型的有效性,但三维头部建模的宽视角渲染、表情驱动和外貌编辑等方面的性能仍然不足。南京大学智能科学与技术学院三维视觉实验室(NJU-3DV)针对此任务,提出在数量有限的高精度三维模型数据的基础之上,训练出360度可渲染的数字人头部参数化模型。该模型将面部运动、外形和外貌解耦,分别由参数化三维网格模型和神经纹理表示,同时提出了一种新型训练方法,用于分解头发和面部外貌,支持发型的自由更换。
具体而言,所提出的参数化头部模型由一个六平面神经辐射场表示,以生成神经纹理和参数化的三维网格模型为条件输入。该模型将面部外观、形状和运动分别参数化为纹理编码、形状编码和表情基参数,实现了基于单张图像输入的高质量三维模型拟合。所提出的模型是第一个支持360度自由视角合成、图像拟合和表情驱动的头部参数化模型,实验结果表明,该模型在参数空间中实现了面部运动和外貌的精确解耦,在渲染和驱动质量方面达到了三维数字人头部建模的最高水平。该工作已经被计算机视觉领域顶级会议ECCV 2024 接收。

图:Head360算法结构示意图
工作六:基于材质分解和光线跟踪的高斯点云真实感重光照技术
三维高斯溅射技术因其高效的优化效率、高质量的渲染质量和快速的渲染速度,在新视角合成和三维重建领域引发了一场研究热潮。然而,现有的三维高斯点云表达尚不支持重光照这一重要应用。针对这一问题,南京大学智能科学与技术学院三维视觉实验室(NJU-3DV)提出了一种基于材质分解和光线跟踪的高斯点云真实感重光照技术,以实现照片级真实的重光照效果。
具体而言,该技术在原始三维高斯点云表达之上添加法向量、BRDF参数以及入射光等属性,赋予三维高斯点云可重光照的特性。从多视图影像出发,该技术通过三维高斯喷溅 (3D Gaussian Splatting, 3DGS) 技术优化三维场景,同时通过基于物理的可微渲染分解BRDF和光照。为了在重光照中生成合理的阴影效果,该技术还创新性地在离散点云表征上设计了一种光线追踪方法,结合层次包围体(Bounding Volume Hierarchies, BVH) 结构进行高效的可见性预计算。实验表明,与最先进的方法相比,该技术在BRDF估计、新视图合成和重光照结果方面有显著提升。所提出的框架展示了基于点云的渲染在编辑、光线追踪和重光照上的巨大潜力。该工作已经被国际计算机视觉顶级会议 ECCV2024 接收。

图:基于三维高斯点云表达的多物体组合场景重光照

图:基于三维高斯点云表达的真实场景重光照
工作七:EmoTalk3D:情感可控的高保真自由视角说话动画合成
3D Talking Head生成是指根据输入语音合成一个人说话的三维动画,其核心挑战在于将语音信号准确地映射到嘴唇运动、面部表情和三维外形上。尽管大量研究工作尝试3D Talking Head生成任务,此前的方法在渲染质量、音唇同步性和多视点一致性等方面仍存在问题。此外,先前的研究方法通常忽视了数字人的情感表达,降低了合成视频的真实感。针对这些挑战,南京大学智能科学与技术学院三维视觉实验室(NJU-3DV)提出了一种高保真的情感可控的3D Talking Head生成方法。团队构建了首个包含语音、情感标注、逐帧多视点视频及三维模型的数据集—EmoTalk3D数据集,并基于该数据集提出了基于“语音-几何-外貌”的新型数字人驱动框架。
该方法首先根据音频特征预测出准确的三维模型序列,而后根据预测的几何信息合成以4D高斯为表征的人物动态外貌。其中,人物外貌被进一步分解为基准高斯分量和动态高斯分量,并根据多视点视频信息优化,实现了可自由视角渲染的3D Talking Head模型。此外,通过从输入语音中提取情感标签,实现了3D Talking Head的情感可控性。该方法呈现出较高的渲染质量、稳定的唇音同步性、清晰的动态面部细节及准确生动的情感表达,实验结果验证了该方法在情感可控的人物说话视频生成上的有效性。该工作已经被计算机视觉顶级会议ECCV 2024接收。

图:EmoTalk3D算法结构示意图