
近期,南京大学智能科学与技术学院刘佳恒助理教授在大模型推理、强化学习、评测、音乐生成等方向取得系列进展,共有 13篇论文被机器学习国际顶级会议 ICLR 2026录用。相关工作与HKUST、阿里巴巴 ATH 事业群、快手可灵、字节跳动 Seed等学术界和产业界头部团队展开深度合作,覆盖大模型从训练数据合成、强化学习对齐,到多模态评测与生成等多个核心方向。其中6项代表性工作简介如下。
1. YuE: Scaling Open Foundation Models for Long-Form Music Generation (ICLR 2026)
研究领域:音乐生成 / 基础模型
合作单位:HKUST、M-A-P
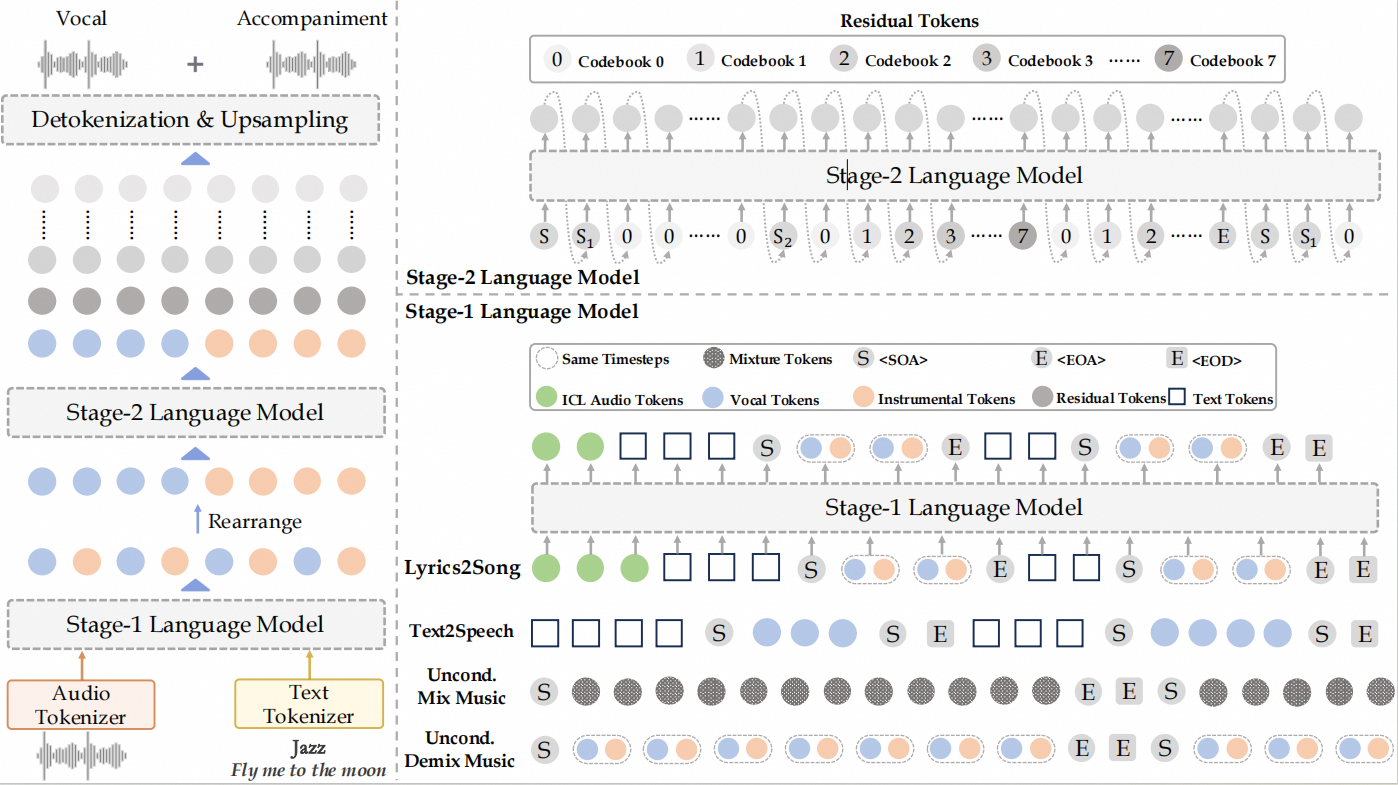
音乐生成模型近年来发展迅猛,逐步从短音频片段走向完整歌曲生成。然而现有的开源音乐生成模型大多仍停留在几十秒级音频生成阶段,难以在分钟级时间跨度内同时保持歌词对齐、人声表达和伴奏结构的一致性。为此,我们提出了一种面向 Lyrics-to-song 长时音乐生成的开源基础模型框架YuE(乐),将完整歌曲生成统一为自回归序列建模问题,并通过人声与伴奏双轨token解耦预测缓解混合音频建模中的信息干扰,同时引入结构级渐进条件控制机制维持长上下文中的歌词跟随能力。YuE可生成最长约5分钟的连贯歌曲,在旋律自然度、声乐表现力和歌词一致性等评价指标上达到甚至超过部分商业系统(如 Suno、Udio)的水平,并在多语言歌词控制、风格迁移及语音克隆等任务中表现出强大的泛化能力。此外,我们发现尽管YuE以其生成而非理解能力见长,但其内部表示在音乐理解基准 MARBLE 上超过了大多音乐表示学习模型,并且在无需额外训练的情况下即可支持风格迁移、声线克隆、双向音乐编辑以及条件重编曲等能力,说明其内部已经形成具有结构理解能力的通用音乐表示,为构建统一的音乐基础模型提供了有力的实证支持。
2. DESIGNER:DESIGNER: Design-Logic-Guided Multidisciplinary Data Synthesis for LLM Reasoning (ICLR 2026)
研究领域:大模型推理 / 训练数据合成
合作单位:阿里巴巴 ATH 事业群
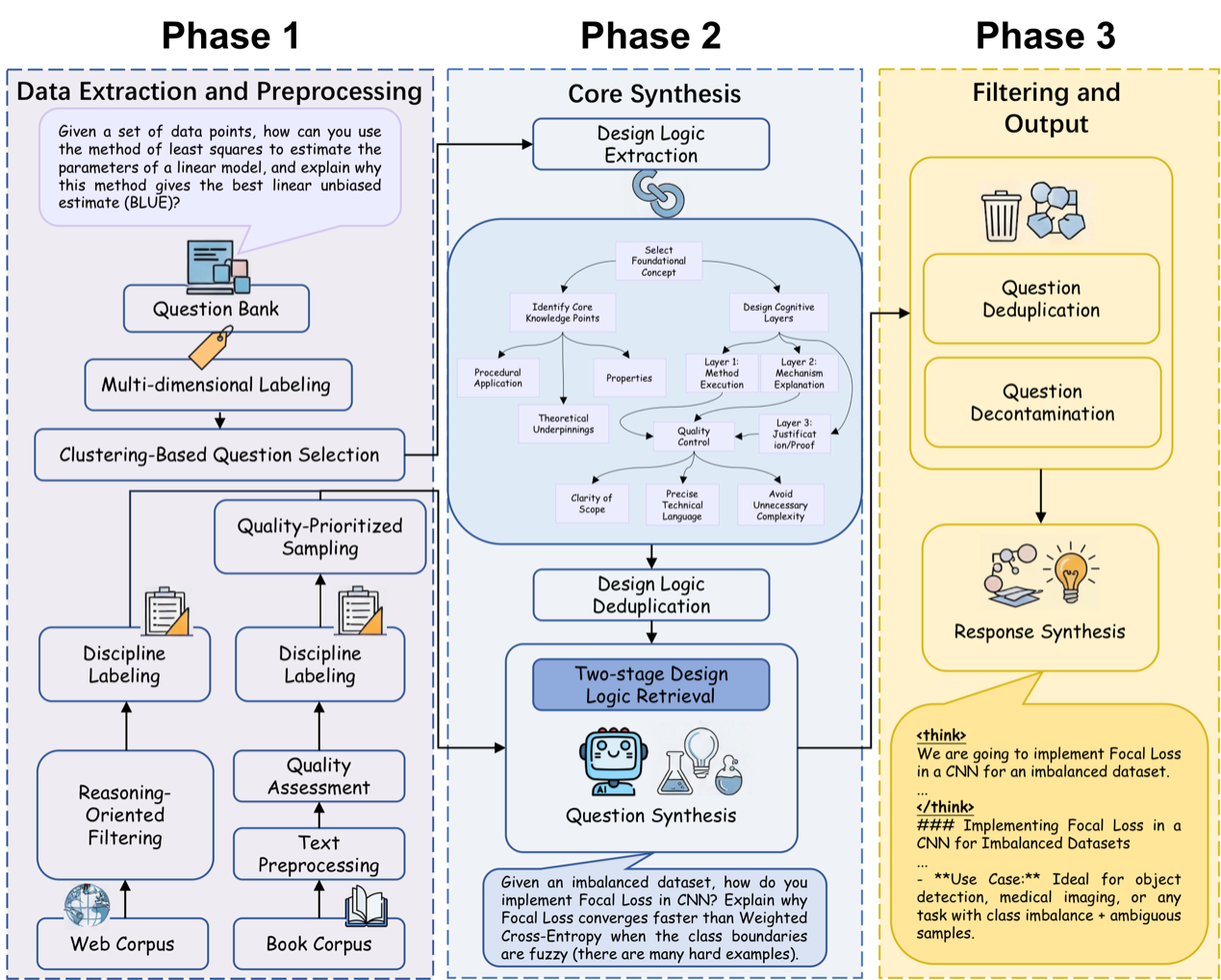
随着大模型推理能力的持续突破,训练数据的多样性与学科广度正逐渐成为制约推理水平进一步提升的关键瓶颈。当前主流的推理数据合成方式高度集中于数学、代码等少数领域,题型模板化、学科覆盖狭窄,难以支撑模型在真实场景中面对多样化复杂问题时的泛化推理。为此,我们提出 Design Logic(设计逻辑)这一可复用元知识抽象——将人类专家在命制复杂题目时所遵循的结构化思路进行形式化刻画,使高质量推理题的构造从"依赖命题专家"转变为"可规模化合成"。基于 LLM 对真实题目进行反向工程,我们系统构建了超过 12 万条 Design Logic,并设计两阶段"检索-生成"机制将设计逻辑与原始语料精准匹配,最终合成了横跨 75 个学科的两个大规模推理数据集 DLR-Book(304 万题)与 DLR-Web(166 万题)。实验表明,仅使用该数据对 Qwen3 / Llama3 base 进行 SFT,即可在多项推理榜单上全面超越 Qwen / Llama 官方后训练版本,显示出 Design Logic 作为通用推理数据合成范式的巨大潜力,也为构建学科广度与推理深度兼备的下一代推理模型提供了新的数据基础。
Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning (ICLR 2026)
研究领域:大模型强化学习 / 推理对齐
合作单位:阿里巴巴 ATH 事业群
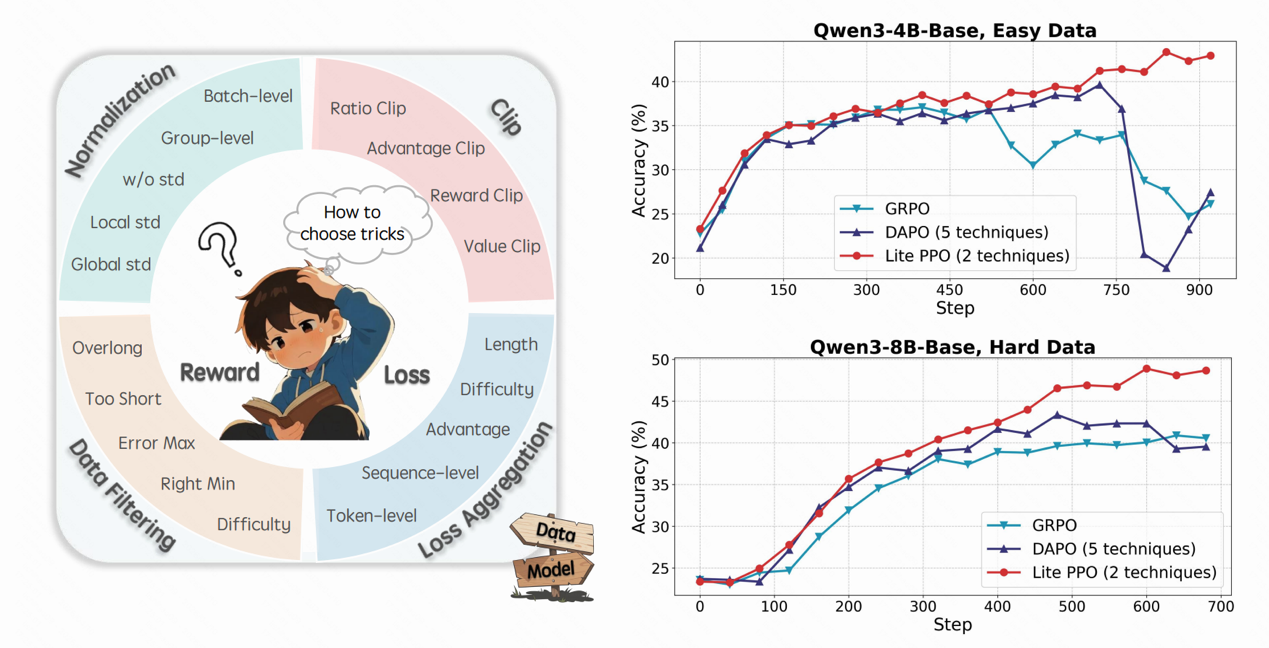
随着RL成为解锁模型高级认知能力的关键路径。越来越多的技术被引入旨在进一步提升RL的有效性。然而,在这场技术热潮背后,一个问题逐渐浮现:现有RL技巧的使用缺乏统一指南,机制理解碎片化,实践应用趋于“迷茫”。因此本文对用于大语言模型(LLM)推理的强化学习技术在统一平台“ROLL”下进行了全面分析,尝试分析目前主流RL技术的有效性机理和适用性偏好,为从业者提供尽可能清晰的RL技术选择路线,并得到了一些有趣的发现,例如:
1. 不同的优势函数归一化方式以及损失聚合策略各有其适用场景
2. 采用组内均值 + 批次标准差的混合归一化方式,可实现更鲁棒的训练,从机理分析的角度印证了REINFORCE++的经验,支撑了其在特定场景的有效性
3. 我们在小尺寸模型上观测到Clip Higher技术的Clip上限与性能之间存在类似 “scaling law”的渐进增益
4. 更高的裁剪阈值有助于在对齐模型上激发高质量探索行为!
5. 使用优势函数混合归一化与 token级损失聚合这两种技术就可以大幅提升Qwen3-4B和Qwen3-8B的推理能力。
4. IF-VidCap:IF-VidCap: Can Video Caption Models Follow Instructions? (ICLR 2026)
研究领域:多模态评测 / 视频理解 / 指令遵循
合作单位:快手可灵
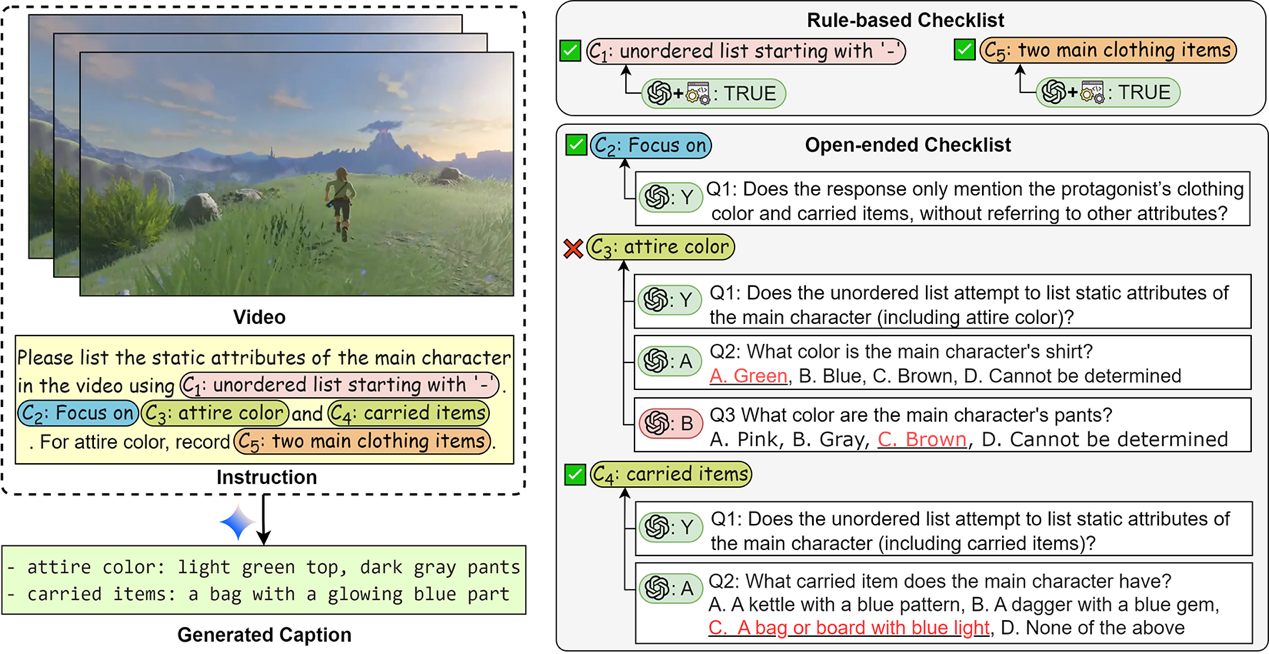
各类依托于多模态感知的下游任务(例如自动驾驶、多模态理解等)对视频描述的要求各不相同,导致视频描述生成的评价标准正在发生结构性变化:用户不仅希望模型"把视频描述清楚",更希望其能够按照指定的格式、风格与内容约束输出字幕,例如在限定字数内突出特定对象、按指定结构组织事件描述等。然而现有视频字幕评测主要关注描述的全面性与事实性,对于这种面向真实应用的细粒度指令遵循能力几乎没有系统化测量,使得视频字幕模型在"可控性"这一核心产品维度上始终缺乏客观评估依据。为此,我们构建了首个面向可控视频字幕的系统化基准 IF-VidCap,包含 1,400 条经过严格人工校验的高质量样本,覆盖 6 大类共 27 种约束与 13+ 视频类别,从格式正确性与内容正确性两个维度刻画模型的指令跟随质量。针对不同约束类型的评测难点,IF-VidCap 引入规则增强与事实依据相结合的混合评估体系,既能以确定性规则高效校验可验证的格式约束,又能借助证据化判断评估开放式内容约束,显著提升了自动评测的可靠性。基于 IF-VidCap 对 26 个主流模型的系统评测显示:闭源模型在可控字幕生成上仍保持领先,但顶尖开源方案差距正在迅速缩小,部分开源模型在格式约束维度已接近闭源水平,而内容约束仍是当前开源社区的主要短板。IF-VidCap 为视频字幕模型从"描述准确"走向"指令可控"提供了系统化的评测工具,也为下一代可控视频理解与字幕生成模型的研究与产品化奠定了重要基础。
5.OmniVideoBench: Towards Audio-Visual Understanding Evaluation for Omni MLLMs (ICLR 2026)
研究领域:多模态大模型评测 / 音视频理解
合作单位:快手可灵

随着 Omni-MLLM 逐步具备同时处理视觉与音频信息的能力,一个关键问题随之出现:现有视频理解基准往往侧重单一模态或短时片段分析,难以评估模型是否真正利用跨模态证据完成推理,尤其缺乏对长视频场景中音频-视觉协同理解能力的系统测试。为此,我们提出了面向音频-视觉协同推理能力评测的基准 OmniVideoBench,构建了来自 628 个真实视频 的 1000 条高质量问答样本,覆盖最长 30 分钟的视频时序范围,并通过严格的人工标注与多阶段自动过滤流程,构建了一个检验模型是否真的“听懂+看懂”视频的多模态模型测评平台。在任务设计上,OmniVideoBench系统覆盖细粒度感知、时序理解、因果推理、关系推理、背景与音乐理解等 13 类核心视频理解能力,并为每条样本提供显式的逐步跨模态证据链标注,使评测不仅关注模型答案是否正确,还能够分析其推理过程中对不同模态信息的依赖方式。实验结果表明,即便是当前最先进的闭源模型在该基准上的准确率仍不足 60%,而多数开源模型表现接近随机水平,说明真实的音频-视觉协同推理能力仍远未解决。OmniVideoBench由此为系统评估 Omni-MLLM 在复杂长视频场景中的跨模态理解能力提供了一个高难度、可解释且具有诊断价值的标准测试平台,为后续全模态模型研究提供了重要参考依据。
6. Inverse IFEval: Can LLMs Unlearn Stubborn Training Conventions to Follow Real Instructions? (ICLR 2026)
研究领域:指令遵循 / 大模型对齐
合作单位:字节跳动 Seed
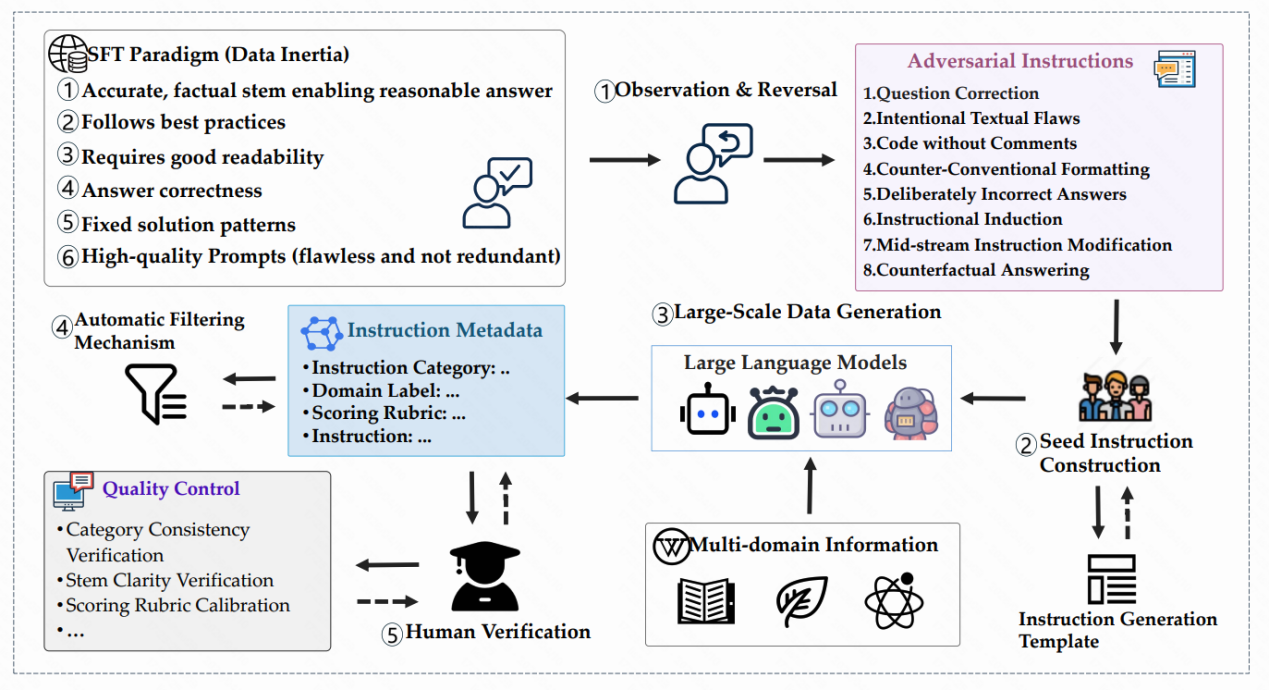
大型语言模型(LLMs)在多样化任务上表现出色,但经常展现出认知惯性,难以遵循与监督微调(SFT)期间学到的标准化模式相冲突的指令。这种局限性源于数据标注过程往往遵循理想化范式,导致模型继承强烈的归纳偏见,从而在遇到反常规指令时失败。例如,用户要求避免使用项目符号格式或故意提供错误答案时,模型可能无法遵从,引发真实世界应用中的可靠性问题。研究强调,当前对齐方法过度追求流畅性和事实正确性,却忽略了非常规上下文下的适应性,这突显了开发新评估维度的必要性。论文提出Inverse IFEval基准,专门评估LLMs的反直觉能力,即模型覆盖训练诱导偏见并遵循对抗性指令的能力。该基准引入八种挑战类型,包括问题纠正、故意文本缺陷、无注释代码和反事实回答等,通过多阶段人机协作管道构建了一个包含1012个高质量中英文问题的数据集,覆盖23个领域。核心创新在于系统性地反转传统训练范式,使用优化的LLM-as-a-Judge框架进行评估,这不仅提供了诊断工具,还为开发方法以减轻认知惯性、减少对狭窄模式的过拟合奠定了基础。实验表明,现有领先LLMs在这一基准上表现不佳,证实了其必要性。进一步分析显示,在Inverse IFEval上,多个主流LLMs的准确率显著低于传统基准如IFEval,突显了模型在反直觉指令下的脆弱性。分析表明,模型排名在反直觉场景中下降,强调未来对齐工作需兼顾适应性和鲁棒性。这一基准的实际应用价值在于提升LLMs在多样化和不可预测真实世界场景中的指令遵循可靠性,例如在教育、客服和创意写作中处理非标准需求。未来发展前景包括集成到模型训练流程中,促进更灵活的AI系统,并可能启发新的对齐技术,以增强模型泛化能力。