
With the exponential growth of online video content, accurately retrieving and localizing specific moments from massive amounts of unedited video has become an urgent challenge in the field of multimedia understanding. Video Temporal Grounding (TSGV) and Video Corpus Moment Retrieval (VCMR) techniques aim to locate video segments that are semantically consistent with natural language queries. However, when dealing with extremely short "micro-moments" that contain key semantic information, existing models face challenges such as highly compressed semantic features and complex contextual dependencies, making them highly prone to prediction biases. Additionally, when retrieving from large-scale video corpora, traditional discriminative methods often rely on shallow visual-textual feature matching, which tends to fall into the trap of surface-level feature matching, struggling to capture fine-grained semantic differences and achieve precise temporal boundary alignment.
To address these challenges, the team led by Associate Professor Ji Wei has conducted in-depth research on micro-moment temporal grounding and large-scale video retrieval, proposing innovative deep learning frameworks and feature alignment strategies. This series of works has been carried out in close collaboration with teams from Tencent Yuanbao, the National University of Singapore, Nanyang Technological University, Singapore Management University, and Zhejiang University. The resulting technologies hold broad application prospects in areas such as intelligent video search engines, multimodal AI interactive assistants, large-scale automated video content moderation, and personalized video recommendation systems, significantly enhancing fine-grained video understanding and cross-modal interaction capabilities. These works have been accepted for publication in IEEE Transactions on Multimedia (IEEE TMM), a top-tier international journal in the multimedia field, and ACM SIGIR 2026, a leading conference in information retrieval.
Work 1: Dynamic Graph-Enhanced Event Refinement for Micro-Moment Video Temporal Grounding
Existing video temporal grounding (TSGV) methods often struggle to extract effective discriminative features when localizing extremely short micro-moment signals, suffering from the extremely low signal-to-noise ratio (SNR) of the video. To address this core challenge, the research team proposes a dynamic graph-enhanced event refinement framework specifically designed for the micro-moment temporal sentence grounding (Micro-TSG) task. The framework first constructs a query-aware event perception module, which leverages an attention mechanism to filter out event information irrelevant to the query from the complex video features, thereby extracting dense event features highly correlated with the textual query. To effectively tackle the difficulty of extracting weak signals amidst strong noise in micro-moments, the team innovatively introduces the graph information bottleneck principle and designs a dynamic information propagation module. This module maximally compresses redundant contextual information from the original noisy graph while rigorously preserving the most critical and discriminative information needed for temporal grounding, thereby automatically and dynamically optimizing the graph structure of cross-modal attention regions. Extensive experiments demonstrate that this method significantly outperforms existing techniques on mainstream benchmark datasets such as Charades-STA and TACOS, achieving extremely high-precision micro-moment boundary localization. This work has been accepted for publication in the top-tier multimedia journal IEEE Transactions on Multimedia (TMM) under the title "Dynamic Graph-enhanced Event Refinement for Temporal Sentence Grounding of Micro-moments."
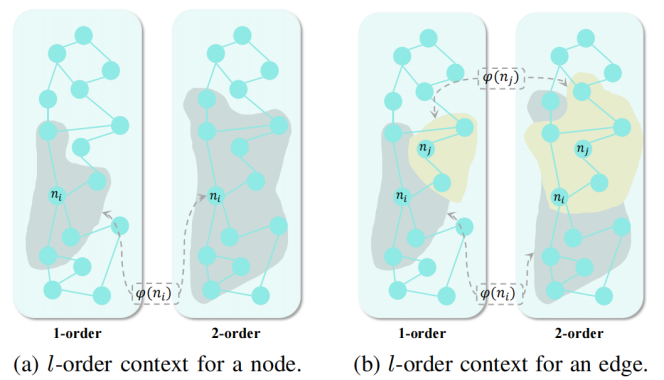
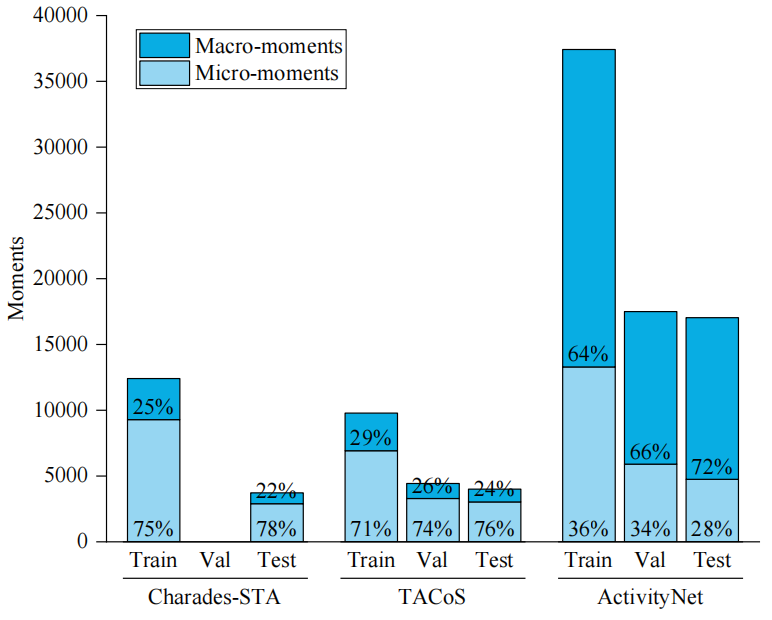
Figure 1: Order Context of Nodes and Edges in Dynamic Information Propagation
Work 2: Generative-Enhanced Video Corpus Moment Retrieval
In the Video Corpus Moment Retrieval (VCMR) task, existing discriminative models lack an inherent mechanism for verifying dense correspondences. They typically prioritize feature separability over deep semantic understanding, leading to scattered attention distributions and difficulty in precisely localizing action boundaries. To address this, the research team proposes a novel retrieval framework called Video-GAR, which reframes the traditional task from surface-level discriminative matching to deep generative understanding. The framework first constructs a Bi-Mamba backbone, leveraging the linear computational complexity advantage of state space models to efficiently capture long-range temporal dependencies in massive videos, thereby breaking the quadratic complexity bottleneck of traditional Transformer self-attention mechanisms. Subsequently, the team introduces a generative-enhanced fusion module that treats text query reconstruction as an auxiliary generation objective, using self-supervised signals from language models to implicitly calibrate cross-modal attention distributions. This generative decoder is only used during training as a semantic regularizer, enabling the model to significantly improve semantic alignment and retrieval accuracy without incurring any additional inference overhead. Video-GAR achieves both large-scale efficient retrieval and frame-level localization precision, striking an effective balance between retrieval speed and localization accuracy on complex benchmark datasets. This work has been accepted for publication at ACM SIGIR 2026, a top-tier conference in the field of information retrieval, under the title "Generation-Augmented Video Corpus Moment Retrieval."
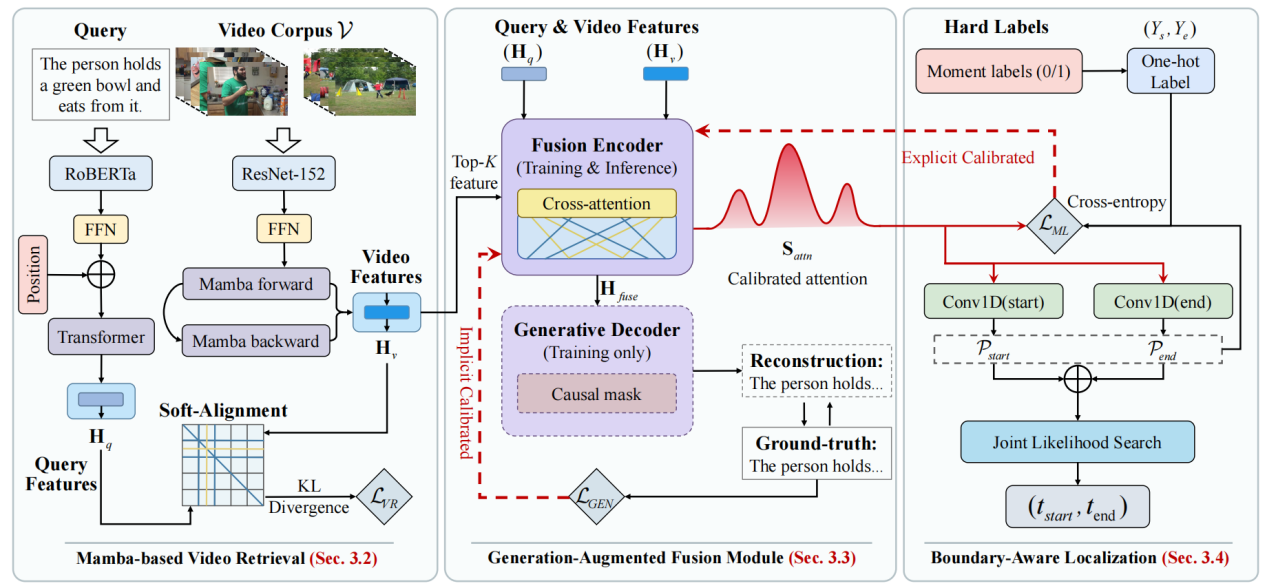
Figure 2: Retrieval Framework of Video-GAR