
Recently, Assistant Professor Liu Jiaheng from the School of Intelligence Science and Technology at Nanjing University has achieved a series of advancements in areas including large model inference, reinforcement learning, and benchmarking 、 music generation. A total of 13 of his papers have been accepted at ICLR 2026, a top-tier international conference in machine learning. These works involve deep collaborations with leading academic and industrial teams, including HKUST, Alibaba ATH Business Group, Kuaishou Kling, and ByteDance Seed, covering core directions such as training data synthesis for large models, reinforcement learning alignment, and multimodal evaluation and generation. Six representative works are briefly introduced as follows.
1. YuE: Scaling Open Foundation Models for Long-Form Music Generation (ICLR 2026)
Research Areas: Music Generation / Foundation Models
Collaborating Institutions: HKUST, M-A-P
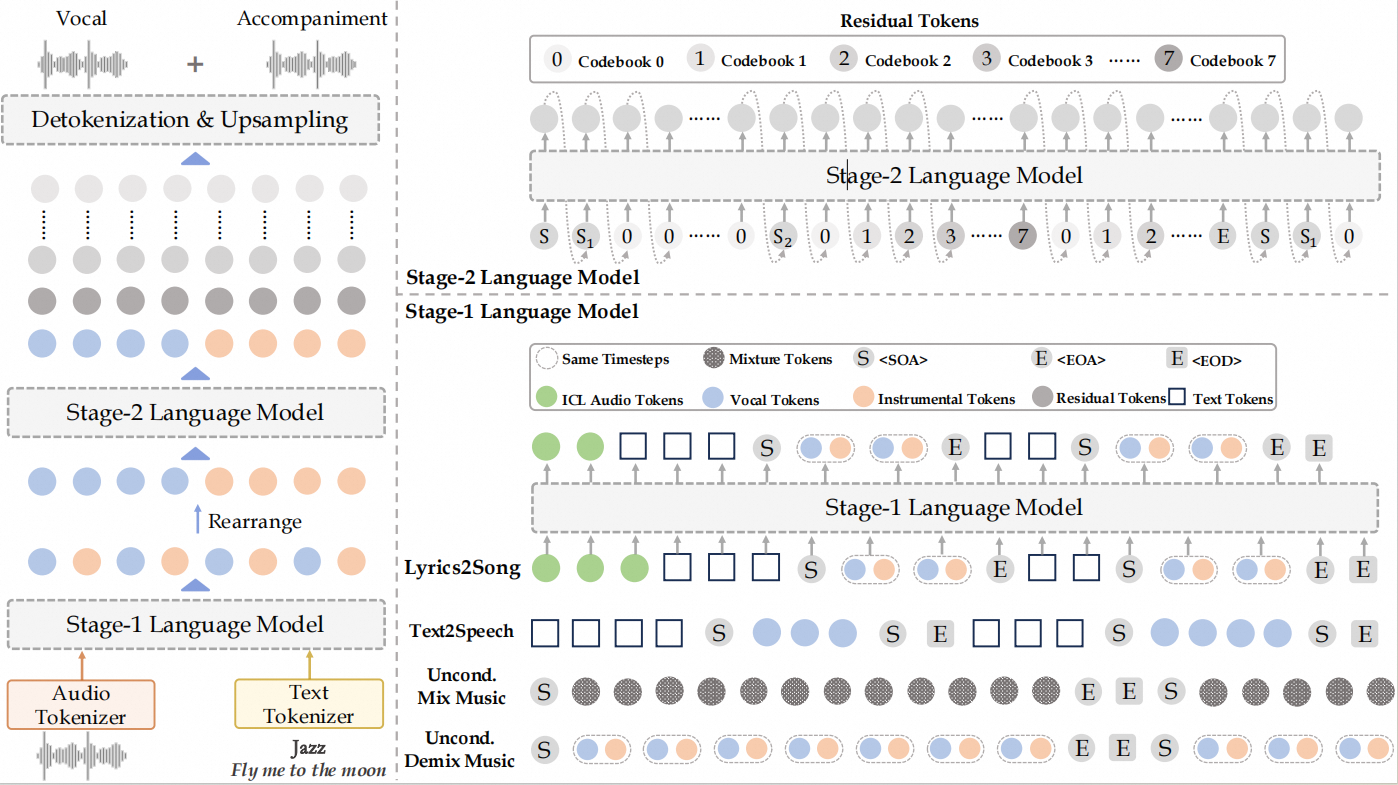
In recent years, music generation models have developed rapidly, gradually evolving from short audio clips to full-length song generation. However, most existing open-source music generation models remain at the stage of generating audio at the scale of tens of seconds, struggling to maintain consistency in lyric alignment, vocal expression, and accompaniment structure over minute-long time spans. To address this challenge, we propose YuE, an open-source foundation model framework for long-form lyrics-to-song music generation. YuE formulates full-song generation as an autoregressive sequence modeling problem. It employs a dual-track token prediction approach for vocals and accompaniment to mitigate information interference in mixed audio modeling, while introducing a structure-level progressive conditional control mechanism to maintain lyric-following capability over long contexts. YuE can generate coherent songs of up to approximately five minutes, achieving or even surpassing the performance of some commercial systems (e.g., Suno, Udio) in terms of melodic naturalness, vocal expressiveness, and lyric consistency. It also demonstrates strong generalization capabilities in tasks such as multilingual lyric control, style transfer, and voice cloning. Furthermore, we find that although YuE is primarily designed for generation rather than understanding, its internal representations outperform most music representation learning models on the MARBLE music understanding benchmark. Moreover, without any additional training, YuE supports capabilities such as style transfer, voice cloning, bidirectional music editing, and conditional rearrangement, indicating that it has developed a general-purpose music representation with structural understanding. This provides strong empirical support for the development of unified music foundation models.
2. DESIGNER:DESIGNER: Design-Logic-Guided Multidisciplinary Data Synthesis for LLM Reasoning (ICLR 2026)
Research Areas: Large Model Inference / Training Data Synthesis
Collaborating Institutions: Alibaba ATH Business Group
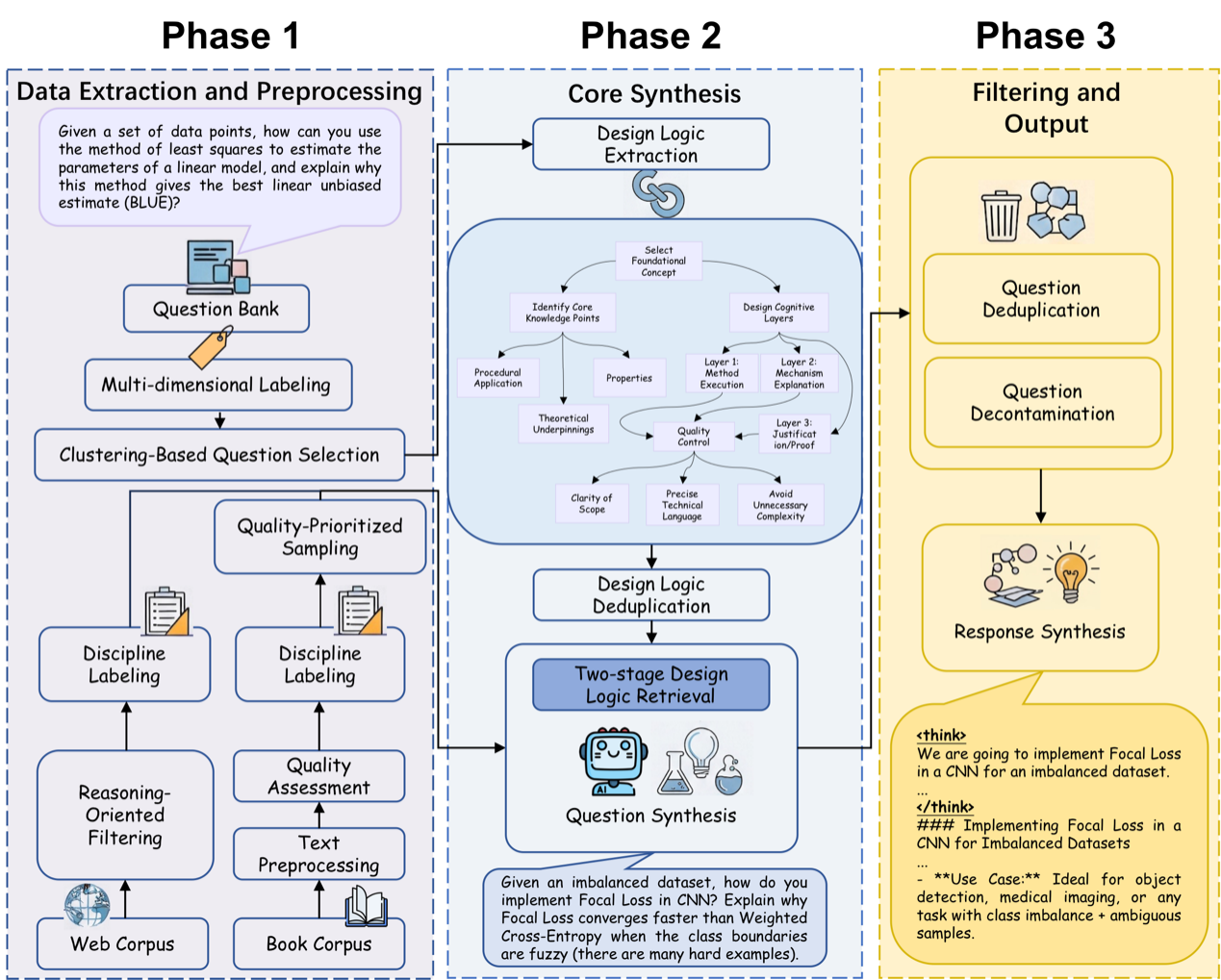
As the reasoning capabilities of large language models continue to advance, the diversity and disciplinary breadth of training data are increasingly becoming critical bottlenecks limiting further improvements in reasoning performance. Current mainstream approaches to reasoning data synthesis are heavily concentrated in a few domains such as mathematics and coding, characterized by templated problem types and narrow subject coverage, making it difficult to support models' generalization across diverse, complex real-world reasoning scenarios.To address this, we propose Design Logic, a reusable meta-knowledge abstraction that formalizes the structured reasoning processes human experts follow when crafting complex problems. This transforms the construction of high-quality reasoning problems from relying on expert problem designers to scalable synthesis. By reverse-engineering real-world problems using LLMs, we systematically construct over 120,000 Design Logic entries. We then design a two-stage retrieve-and-generate mechanism to accurately match Design Logic with source corpora, ultimately synthesizing two large-scale reasoning datasets spanning 75 disciplines: DLR-Book (3.04 million problems) and DLR-Web (1.66 million problems).Experimental results show that simply fine-tuning Qwen3/Llama3 base models on this data enables them to comprehensively surpass the official post-trained versions of Qwen/Llama across multiple reasoning benchmarks. This demonstrates the significant potential of Design Logic as a general-purpose paradigm for reasoning data synthesis, and provides a new data foundation for building next-generation reasoning models that combine both disciplinary breadth and reasoning depth.
Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning (ICLR 2026)
Research Areas: Large Model Reinforcement Learning / Reasoning Alignment
Collaborating Institutions: Alibaba ATH Business Group
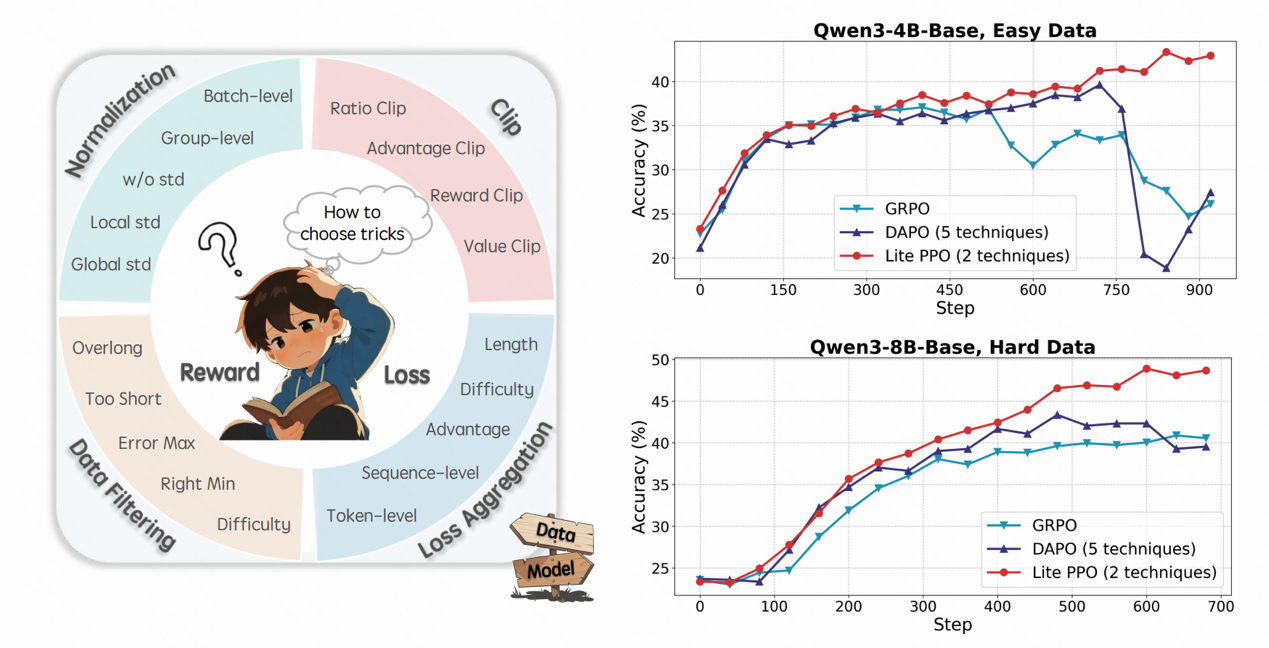
As reinforcement learning (RL) becomes a key pathway for unlocking advanced cognitive capabilities in models, an increasing number of techniques are being introduced to further enhance the effectiveness of RL. However, beneath the surface of this technological热潮, a question has gradually emerged: existing RL techniques lack unified guidance for their use, mechanistic understanding remains fragmented, and practical applications are becoming increasingly lost in confusion. Therefore, this paper presents a comprehensive analysis of reinforcement learning techniques for large language model (LLM) reasoning under a unified platform called ROLL. We attempt to analyze the effectiveness mechanisms and applicability preferences of current mainstream RL techniques, providing practitioners with a clear roadmap for selecting RL techniques. Several interesting findings have emerged, for example:
1.Different advantage function normalization methods and loss aggregation strategies each have their own applicable scenarios.
2.Hybrid normalization (intra-group mean + batch-level standard deviation) leads to more robust training, confirming the empirical findings of REINFORCE++ and supporting its effectiveness in specific scenarios from a mechanistic standpoint.
3.On small-scale models, we observe a progressive gain between the clip upper bound of the Clip Higher technique and model performance, resembling a scaling law.
4.A higher clipping threshold helps stimulate high-quality exploration behavior in aligned models!
5.Using hybrid advantage normalization and token-level loss aggregation significantly enhances the reasoning capabilities of Qwen3-4B and Qwen3-8B.
4. IF-VidCap:IF-VidCap: Can Video Caption Models Follow Instructions? (ICLR 2026)
Research Areas: Multimodal Evaluation / Video Understanding / Instruction Following
Collaborating Institution: Kuaishou Kling
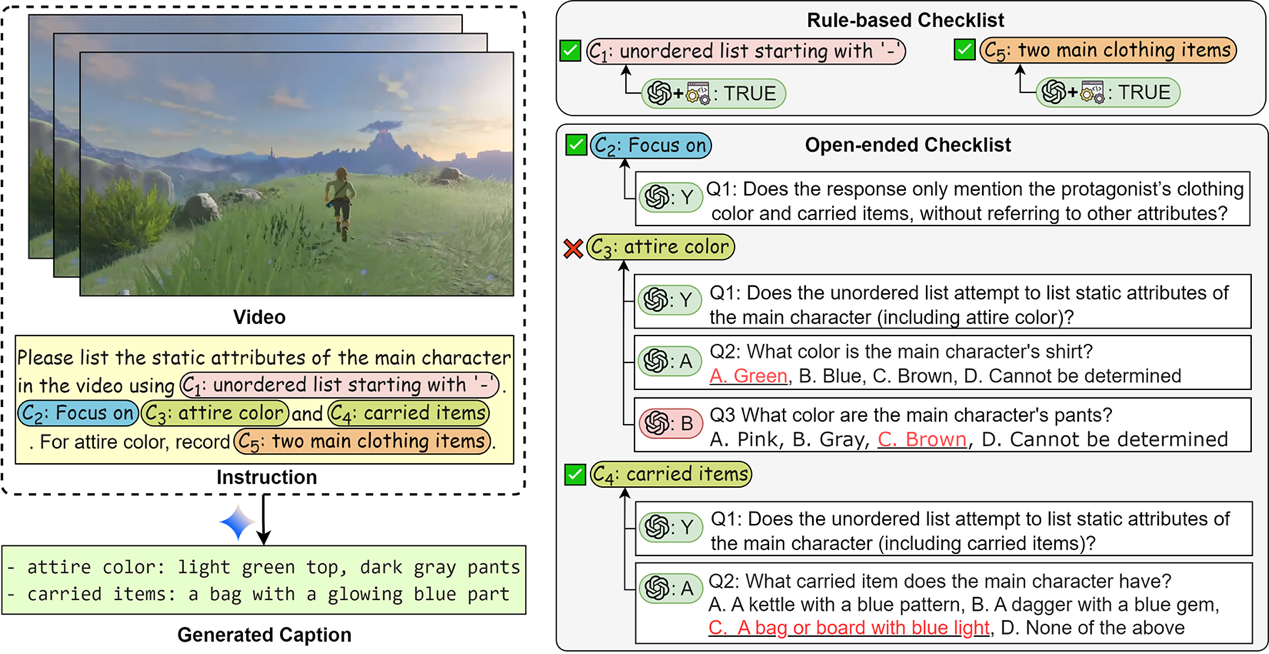
Various downstream tasks that rely on multimodal perception—such as autonomous driving and multimodal understanding—have differing requirements for video captioning, leading to a structural shift in the evaluation criteria for video caption generation. Users now expect models not only to describe the video clearly, but also to generate captions that adhere to specified formats, styles, and content constraints—for example, highlighting specific objects within a limited word count, or organizing event descriptions according to a given structure.However, existing video captioning benchmarks primarily focus on comprehensiveness and factual accuracy, with virtually no systematic measurement of fine-grained instruction-following capabilities for real-world applications. As a result, the core product dimension of controllability in video captioning models has long lacked an objective evaluation basis.To address this gap, we construct IF-VidCap, the first systematic benchmark for controllable video captioning. It comprises 1,400 high-quality samples, each rigorously manually verified, covering 6 major categories encompassing 27 types of constraints and over 13 video genres. IF-VidCap evaluates model instruction-following quality from two dimensions: format correctness and content correctness.To address the evaluation challenges posed by different constraint types, IF-VidCap introduces a hybrid evaluation framework combining rule-based enhancement and evidence-based assessment. This framework efficiently verifies verifiable format constraints through deterministic rules, while evaluating open-ended content constraints via evidence-grounded judgment, significantly improving the reliability of automatic evaluation.Systematic evaluation of 26 mainstream models based on IF-VidCap reveals that while closed-source models still lead in controllable caption generation, the gap with top open-source models is rapidly narrowing. Some open-source models approach closed-source performance on format constraints, but content constraints remain a major shortcoming for the open-source community.IF-VidCap provides a systematic evaluation tool for video captioning models to transition from descriptive accuracy to instruction-based controllability, and establishes a critical foundation for research and productization of next-generation controllable video understanding and captioning models.
5.OmniVideoBench: Towards Audio-Visual Understanding Evaluation for Omni MLLMs (ICLR 2026)
Research Areas: Multimodal Large Model Evaluation / Audio-Visual Understanding
Collaborating Institution: Kuaishou Kling

As Omni-MLLM gradually acquires the ability to handle both visual and audio information simultaneously, a key issue emerges: existing video understanding benchmarks often focus on single modality or short-time segment analysis, making it difficult to assess whether the model truly utilizes cross-modal evidence for reasoning, especially lacking systematic tests for audio-visual collaborative understanding in long video scenarios. To address this, we propose OmniVideoBench, a benchmark for evaluating audio-visual collaborative reasoning capabilities. We have constructed 1,000 high-quality question-answer samples from 628 real videos, covering a video temporal range of up to 30 minutes, and through rigorous manual annotation and multi-stage automatic filtering processes, have built a multimodal model evaluation platform to test whether the model truly understands both audio and video. In terms of task design, OmniVideoBench covers 13 core video understanding capabilities, including fine-grained perception, temporal understanding, causal reasoning, relational reasoning, background and music understanding, and provides explicit step-by-step cross-modal evidence chain annotations for each sample, enabling the evaluation to not only focus on the correctness of the model's answers but also analyze the way it relies on different modalities during the reasoning process. Experimental results show that even the most advanced closed-source models achieve an accuracy rate of less than 60% on this benchmark, while most open-source models perform at a level close to random, indicating that the true audio-visual collaborative reasoning ability remains far from being solved. Thus, OmniVideoBench provides a high-difficulty, interpretable, and diagnostically valuable standard test platform for systematically evaluating the cross-modal understanding capabilities of Omni-MLLM in complex long-video scenarios, offering an important reference basis for subsequent full-modal model research.
6. Inverse IFEval: Can LLMs Unlearn Stubborn Training Conventions to Follow Real Instructions? (ICLR 2026)
Research Areas: Instruction Following / LLM Alignment
Collaborating Institution: ByteDance Seed
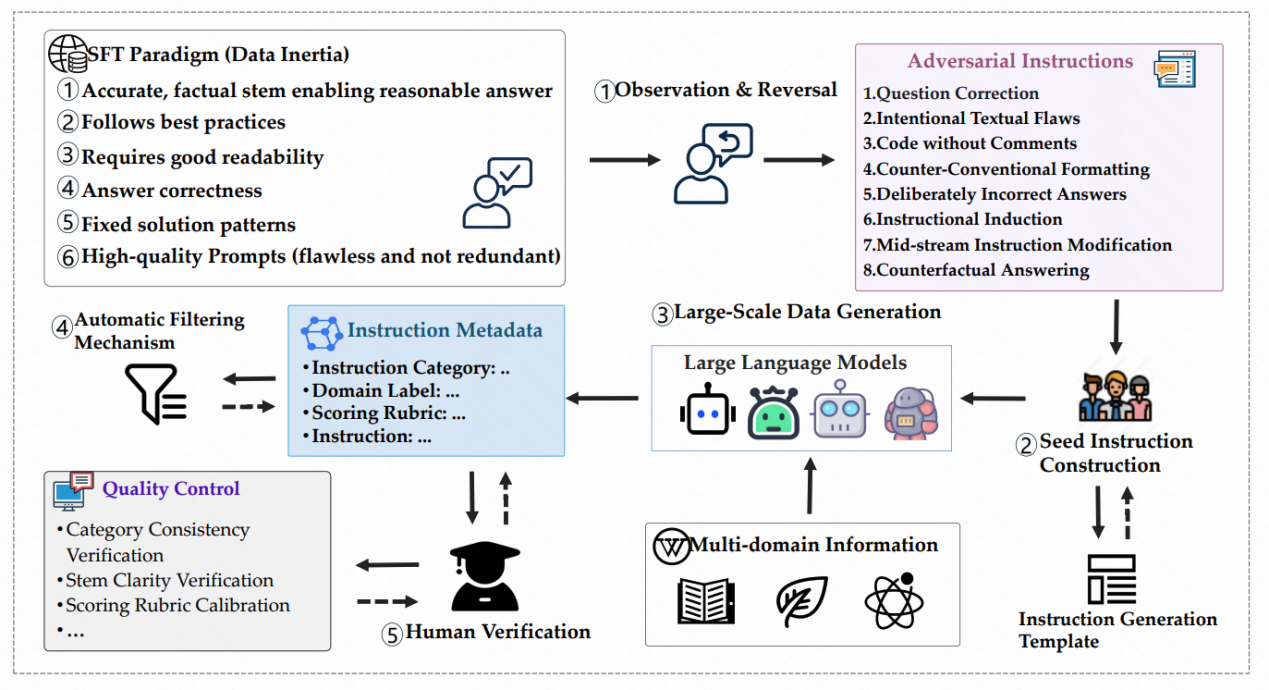
Large language models (LLMs) excel in a variety of tasks but often exhibit cognitive inertia, struggling to follow instructions that conflict with the standardized patterns learned during supervised fine-tuning (SFT). This limitation stems from the data annotation process, which typically adheres to idealized paradigms, leading the models to inherit strong inductive biases and fail when confronted with unconventional instructions. For instance, when users request to avoid bullet-point formatting or deliberately provide incorrect answers, the models may fail to comply, raising reliability concerns in real-world applications. Research highlights that current alignment methods overly focus on fluency and factual correctness while neglecting adaptability in atypical contexts, underscoring the need for new evaluation dimensions. The paper introduces the Inverse IFEval benchmark, specifically designed to assess LLMs' counter-intuitive capabilities, that is, their ability to override training-induced biases and follow adversarial instructions. This benchmark introduces eight challenge types, including problem correction, intentional text flaws, unannotated code, and counterfactual responses, and constructs a dataset of 1,012 high-quality questions in both Chinese and English across 23 domains through a multi-stage human-machine collaborative pipeline. The core innovation lies in systematically reversing the traditional training paradigm and using an optimized LLM-as-a-Judge framework for evaluation, which not only provides a diagnostic tool but also lays the foundation for developing methods to mitigate cognitive inertia and reduce overfitting to narrow patterns. Experiments show that leading LLMs perform poorly on this benchmark, confirming its necessity. Further analysis reveals that the accuracy rates of multiple mainstream LLMs on Inverse IFEval are significantly lower than on traditional benchmarks like IFEval, highlighting the models' vulnerability in counter-intuitive scenarios. The analysis indicates that model rankings decline in counter-intuitive scenarios, emphasizing the need for future alignment efforts to balance adaptability and robustness. The practical value of this benchmark lies in enhancing the reliability of LLMs in following instructions in diverse and unpredictable real-world scenarios, such as handling non-standard requests in education, customer service, and creative writing. Future development prospects include integration into the model training process to promote more flexible AI systems and potentially inspire new alignment techniques to enhance model generalization capabilities.